MySQL数据类型
串
串数据类型存储串。并有定长串与变长串两种类型。串值需要在引号内(单引号最好)。
定长串:接受长度固定的字符串,长度在建表时指定。(处理定长列速度很快):
- CHAR:1-255个字符定长串,默认长度为1。
变长串:存储可变长度的文本。有些变长数据类型具有最大的定长,有些完全变长的。(无法对变长列索引):
- Varchar:长度可变,最大255(2^8^-1)。
- Text:最大长度64K(2^16^)。
- TinyText:最大长度255。
- LongText:最大长度4GB。
- MediumText:最大长度16K。
- ENUM:接受最多64K个串组成应该预定义集合的某个串。
- SET:接受最多64个串组成应该预定义集合的零个或某个串。
数值数据
数值不使用引号,对于货币一般使用Decimal(8,2)。
除了BIT和Boolean都可以由符号或无符号,默认是有符号,可以使用UNSIGNED取消存储负数。
- BIT:1字节,位字段,1~64位。
- BigInt:8字节,整数值,-2^63^~2^63^。
- Boolean:1字节,0或1。
- Decimal:自定义长度,精度可变的浮点值。
- Double:8字节,双精度浮点。
- Float:4或8字节,单精度浮点。
- Int:4字节,整数值-2^31^~2^31^。
- MediumInt:3字节。
- Real:4字节,浮点值。
- SmallInt:2字节。
- TinyInt:1字节。
日期与时间数据类型
- Date:表示YYYY-MM-DD日期。
- DateTime:Date与Time组合。
- TimeStamp:与DateTime相同,但范围较小。
- Time:格式位HH:MM:SS。
- Year:2位数字表示,(19)70
(20)69。4位数字表示:19012155。
二进制数据类型
可以存储任何数据,如图像、多媒体等:
- Blob:最大长度64KB。
- MediumBlob:最大长度16MB。
- LongBlob:最大长度4GB。
- TinyBlob:最大长度255字节。
关系数据库设计理论
函数依赖
记A->B表示A函数决定B,也可以说B函数依赖于A。
如果{A1,A2,… ,An}是关系的一个或多个属性的集合,该集合函数决定了关系的其它所有属性并且是最小的,那么该集合就称为键码。
对于A->B,如果能找到A的真子集A’,使得A’->B,那么A->B就是部分函数依赖,否则就是完全函数依赖。
对于A->B,B->C,则A->C是一个传递函数依赖。
异常
以下的学生课程关系的函数依赖为 Sno, Cname -> Sname, Sdept, Mname, Grade,键码为 {Sno, Cname}。也就是说,确定学生和课程之后,就能确定其它信息。
| Sno | Sname | Sdept | Mname | Cname | Grade |
|---|---|---|---|---|---|
| 1 | 学生-1 | 学院-1 | 院长-1 | 课程-1 | 90 |
| 2 | 学生-2 | 学院-2 | 院长-2 | 课程-2 | 80 |
| 2 | 学生-2 | 学院-2 | 院长-2 | 课程-1 | 100 |
| 3 | 学生-3 | 学院-2 | 院长-2 | 课程-2 | 95 |
不符合范式的关系,会产生很多异常,主要有以下四种异常:
- 冗余数据:例如
学生-2出现了两次。 - 修改异常:修改了一个记录中的信息,但是另一个记录中相同的信息却没有被修改。
- 删除异常:删除一个信息,那么也会丢失其它信息。例如删除了
课程-1需要删除第一行和第三行,那么学生-1的信息就会丢失。 - 插入异常:例如想要插入一个学生的信息,如果这个学生还没选课,那么就无法插入。
范式
范式理论是为了解决以上提到四种异常。
高级别范式的依赖于低级别的范式,1NF 是最低级别的范式。
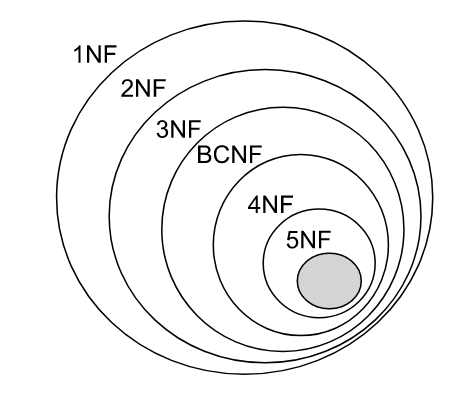
第一范式 (1NF)
属性不可分。
第二范式 (2NF)
每个非主属性完全函数依赖于键码。
可以通过分解来满足。
分解前
| Sno | Sname | Sdept | Mname | Cname | Grade |
|---|---|---|---|---|---|
| 1 | 学生-1 | 学院-1 | 院长-1 | 课程-1 | 90 |
| 2 | 学生-2 | 学院-2 | 院长-2 | 课程-2 | 80 |
| 2 | 学生-2 | 学院-2 | 院长-2 | 课程-1 | 100 |
| 3 | 学生-3 | 学院-2 | 院长-2 | 课程-2 | 95 |
以上学生课程关系中,{Sno, Cname} 为键码,有如下函数依赖:
- Sno -> Sname, Sdept
- Sdept -> Mname
- Sno, Cname-> Grade
Grade 完全函数依赖于键码,它没有任何冗余数据,每个学生的每门课都有特定的成绩。
Sname, Sdept 和 Mname 都部分依赖于键码,当一个学生选修了多门课时,这些数据就会出现多次,造成大量冗余数据。
分解后
关系-1
| Sno | Sname | Sdept | Mname |
|---|---|---|---|
| 1 | 学生-1 | 学院-1 | 院长-1 |
| 2 | 学生-2 | 学院-2 | 院长-2 |
| 3 | 学生-3 | 学院-2 | 院长-2 |
有以下函数依赖:
- Sno -> Sname, Sdept
- Sdept -> Mname
关系-2
| Sno | Cname | Grade |
|---|---|---|
| 1 | 课程-1 | 90 |
| 2 | 课程-2 | 80 |
| 2 | 课程-1 | 100 |
| 3 | 课程-2 | 95 |
有以下函数依赖:
- Sno, Cname -> Grade
第三范式 (3NF)
非主属性不传递函数依赖于键码。
上面的 关系-1 中存在以下传递函数依赖:
- Sno -> Sdept -> Mname
可以进行以下分解:
关系-11
| Sno | Sname | Sdept |
|---|---|---|
| 1 | 学生-1 | 学院-1 |
| 2 | 学生-2 | 学院-2 |
| 3 | 学生-3 | 学院-2 |
关系-12
| Sdept | Mname |
|---|---|
| 学院-1 | 院长-1 |
| 学院-2 | 院长-2 |
ER 图
Entity-Relationship,有三个组成部分:实体、属性、联系。
用来进行关系型数据库系统的概念设计。
实体的三种联系
包含一对一,一对多,多对多三种。
- 如果 A 到 B 是一对多关系,那么画个带箭头的线段指向 B;
- 如果是一对一,画两个带箭头的线段;
- 如果是多对多,画两个不带箭头的线段。
下图的 Course 和 Student 是一对多的关系。

表示出现多次的关系
一个实体在联系出现几次,就要用几条线连接。
下图表示一个课程的先修关系,先修关系出现两个 Course 实体,第一个是先修课程,后一个是后修课程,因此需要用两条线来表示这种关系。
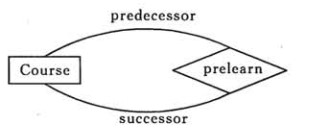
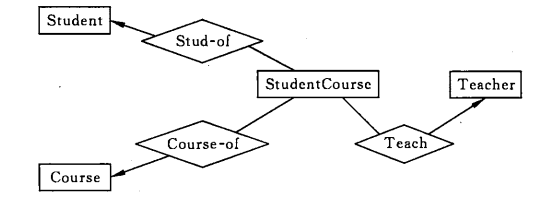
联系的多向性
虽然老师可以开设多门课,并且可以教授多名学生,但是对于特定的学生和课程,只有一个老师教授,这就构成了一个三元联系。

一般只使用二元联系,可以把多元联系转换为二元联系。
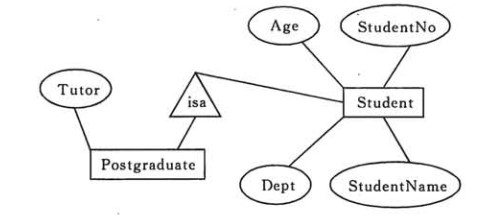
表示子类
用一个三角形和两条线来连接类和子类,与子类有关的属性和联系都连到子类上,而与父类和子类都有关的连到父类上。
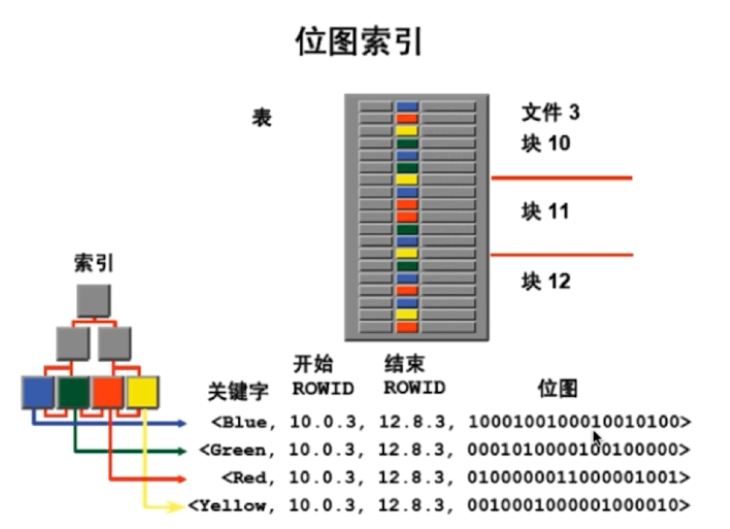
位图Bit Map
当表中的字段仅有几种值,那么Bit Map就是很好的选择。关键字的位图会存该行是否是该关键字。例如10000就是第一行的值是该关键字。因此一个位图能存储非常多的信息。
因此每一列当中只有1个1,其适合查询统计场景。不适合高并发,其粒度非常大,会锁住很多的信息,当增删改查时会涉及比较多的一致性约定。
MySQL
并发一致性问题
在并发环境下,事务的隔离性很难保证,因此会出现很多并发一致性问题。
产生并发不一致性问题主要原因是破坏了事务的隔离性,解决方法是通过并发控制来保证隔离性。并发控制可以通过封锁来实现,但是封锁操作需要用户自己控制,相当复杂。数据库管理系统提供了事务的隔离级别,让用户以一种更轻松的方式处理并发一致性问题。
丢失修改
T1和T2两个事务都对一个数据进行修改,T1先修改,T2随后修改,T2的修改覆盖了T1的修改。
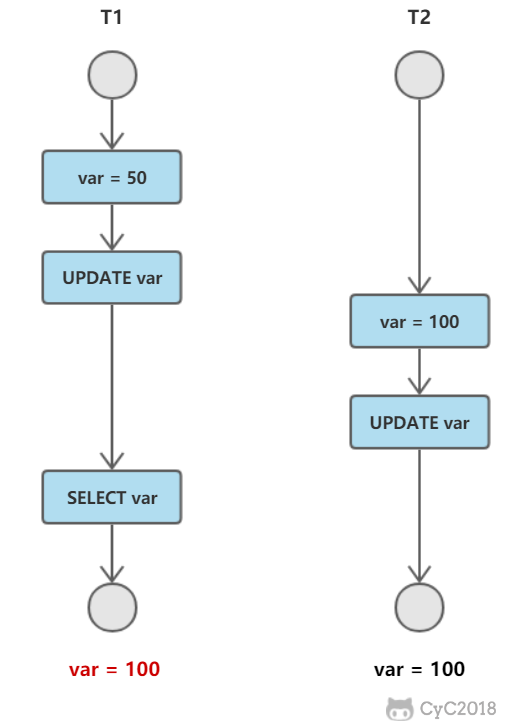
在任何隔离级别下都不会发生,但可能出现另一个问题:
- 事务T1查询一行数据,放入本地内存,显示给一个用户U1。
- 同时,事务T2查询该记录,显式给用户U2。
- U1修改这行记录,更新并提交。
- U2修改这行记录,更新并提交。此时没有去读取新的数据。
- 银行转账场景下会出现问题。
脏读
T1修改一个数据,T2随后读取这个数据。如果T1撤销了这次修改,那么T2读取的数据是脏数据。
脏数据:事务对缓冲池中行记录的修改,并且还没有被提交。
- 如果读到了脏数据,即一个事务读取到另一个事务未提交的数据,违反了数据库的隔离性。
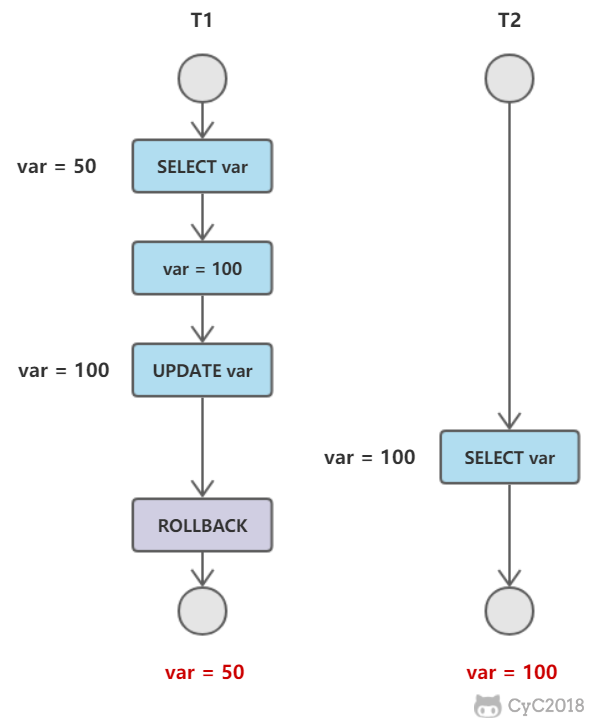
不可重复读
在一个事务内多次读取同一数据集合,在这个事务还没有结束时,另外一个事务也访问该同一数据集合,并做了一些DML操作。
T2读取一个数据,T1对该数据做了修改。如果T2再次读取这个数据,由于T1事务的修改,此时读取的结果和第一次读取的结果不同。
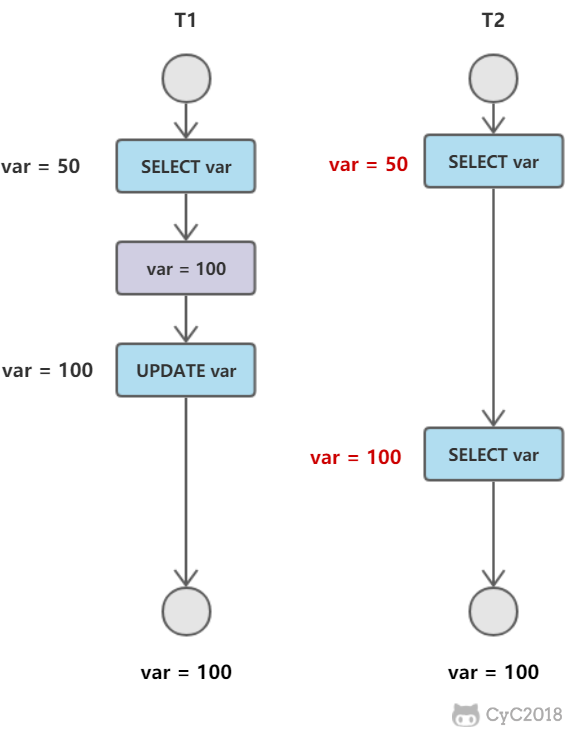
与脏读的区别:
- 脏读读到未提交的数据,不可重复读读取到已经提交的数据。
- 不可重复读违反了数据库事务一致性的要求。
由于读取到的是已经提交的数据,一般而言不会带来很大问题,因此一些数据库允许该现象。
幻读
T1读取某个范围的数据,T2在这个范围内插入新的数据,T1再次读取这个范围的数据,此时读取的结果和和第一次读取的结果不同。
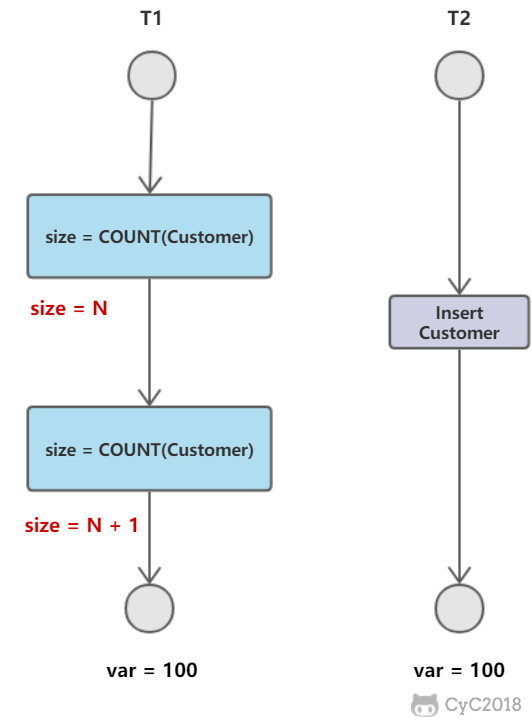
封锁
封锁粒度
MySQL 中提供了两种封锁粒度:行级锁以及表级锁。
应该尽量只锁定需要修改的那部分数据,而不是所有的资源。锁定的数据量越少,发生锁争用的可能就越小,系统的并发程度就越高。
但是加锁需要消耗资源,锁的各种操作(包括获取锁、释放锁、以及检查锁状态)都会增加系统开销。因此封锁粒度越小,系统开销就越大。在选择封锁粒度时,需要在锁开销和并发程度之间做一个权衡。
粒度:database、table、page、row。
封锁类型
读写锁
- 排它锁(Exclusive),简写为X锁,又称写锁。
- 共享锁(Shared),简写为S锁,又称读锁。
有以下两个规定:
- 一个事务对数据对象A加了X锁,就可以对A进行读取和更新。加锁期间其它事务不能对A加任何锁。
- 一个事务对数据对象A加了S锁,可以对A进行读取操作,但是不能进行更新操作。加锁期间其它事务能对A加S锁,但是不能加X锁。
意向锁
使用意向锁(Intention Locks)可以更容易地支持多粒度封锁。
在存在行级锁和表级锁的情况下,事务T想要对表A加X锁,就需要先检测是否有其它事务对表A或者表A中的任意一行加了锁,那么就需要对表A的每一行都检测一次,这是非常耗时的。
意向锁在原来的X/S锁之上引入了IX/IS,IX/IS都是表锁,用来表示一个事务想要在表中的某个数据行上加X锁或S锁。有以下两个规定:
- 一个事务在获得某个数据行对象的S锁之前,必须先获得表的IS锁或者更强的锁。
- 一个事务在获得某个数据行对象的X锁之前,必须先获得表的IX锁。
通过引入意向锁,事务T想要对表A加X锁,只需要先检测是否有其它事务对表A加了X/IX/S/IS锁,如果加了就表示有其它事务正在使用这个表或者表中某一行的锁,因此事务T加X锁失败。
各种锁的兼容关系如下:
| - | X | IX | S | IS |
|---|---|---|---|---|
| X | × | × | × | × |
| IX | × | √ | × | √ |
| S | × | × | √ | √ |
| IS | × | √ | √ | √ |
解释如下:
- 任意IS/IX锁之间都是兼容的,因为它们只是表示想要对表加锁,而不是真正加锁;
- S锁只与S锁和IS锁兼容,也就是说事务T想要对数据行加S锁,其它事务可以已经获得对表或者表中的行的S锁。
封锁协议
三级封锁协议
一级封锁协议
事务T要修改数据A时必须加X锁,直到T结束才释放锁。
可以解决丢失修改问题,因为不能同时有两个事务对同一个数据进行修改,那么事务的修改就不会被覆盖。
| T1 | T2 |
|---|---|
| lock-x(A) | |
| read A=20 | |
| lock-x(A) | |
| wait | |
| write A=19 | . |
| commit | . |
| unlock-x(A) | . |
| obtain | |
| read A=19 | |
| write A=21 | |
| commit | |
| unlock-x(A) |
二级封锁协议
在一级的基础上,要求读取数据A时必须加S锁,读取完马上释放S锁。
可以解决读脏数据问题,因为如果一个事务在对数据A进行修改,根据1级封锁协议,会加X锁,那么就不能再加S锁了,也就是不会读入数据。
| T1 | T2 |
|---|---|
| lock-x(A) | |
| read A=20 | |
| write A=19 | |
| lock-s(A) | |
| wait | |
| rollback | . |
| A=20 | . |
| unlock-x(A) | . |
| obtain | |
| read A=20 | |
| unlock-s(A) | |
| commit |
三级封锁协议
在二级的基础上,要求读取数据A时必须加S锁,直到事务结束了才能释放S锁。
可以解决不可重复读的问题,因为读A时,其它事务不能对A加X锁,从而避免了在读的期间数据发生改变。
| T1 | T2 |
|---|---|
| lock-s(A) | |
| read A=20 | |
| lock-x(A) | |
| wait | |
| read A=20 | . |
| commit | . |
| unlock-s(A) | . |
| obtain | |
| read A=20 | |
| write A=19 | |
| commit | |
| unlock-X(A) |
两段锁协议
两段锁协议是指所有事务必须分两个阶段对数据项加锁和解锁:
在对任何数据进行读、写操作之前,要申请并获得对该数据的封锁。
每个事务中,所有的封锁请求先于所有的解锁请求。
可串行化调度是指,通过并发控制,使得并发执行的事务结果与某个串行执行的事务结果相同。
事务遵循两段锁协议是保证可串行化调度的充分条件。例如以下操作满足两段锁协议,它是可串行化调度。
1 | lock-x(A)...lock-s(B)...lock-s(C)...unlock(A)...unlock(C)...unlock(B) |
但不是必要条件,例如以下操作不满足两段锁协议,但是它还是可串行化调度。
1 | lock-x(A)...unlock(A)...lock-s(B)...unlock(B)...lock-s(C)...unlock(C) |
MySQL隐式与显式锁定
MySQL的InnoDB存储引擎采用两段锁协议,会根据隔离级别在需要的时候自动加锁,并且所有的锁都是在同一时刻被释放,这被称为隐式锁定。
InnoDB也可以使用特定的语句进行显示锁定:
1 | SELECT ... LOCK In SHARE MODE; |
隔离级别
使用隔离级别的开销基本一致。因此即使使用未提交读也不会得到性能的大幅提升:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 未提交读 Read uncommitted | 可能 | 可能 | 可能 |
| 已提交读 Read committed | 可能 | 可能 | |
| 可重复读 Repeatable read | 不可能 | 不可能 | 可能 |
| 可串行化Serializable | 不可能 | 不可能 | 不可能 |
未提交读(Read Uncommitted)
事务中的修改,即使没有提交,对其它事务也是可见的。
允许脏读,也就是可能读取到其他会话中未提交事务修改的数据。
提交读(Read Committed)
一个事务只能读取已经提交的事务所做的修改。换句话说,一个事务所做的修改在提交之前对其它事务是不可见的。Oracle等多数数据库默认都是该级别 (不重复读):
- 不可重复读违反了数据库事务一致性。
- 由于读取到的是已经提交的数据,一般而言不会带来很大问题,因此一些数据库允许该现象。
可重复读(Repeated Read)
保证在同一个事务中多次读取同样数据的结果是一样的。InnoDB默认级别。
采用Next-KeyLock算法避免锁的产生。
串行读(Serializable)
强制事务串行执行。每次读都需要获得表级共享锁,读写相互都会阻塞