分布式锁
为什么需要
- 效率:使用分布式锁可以避免不同节点重复相同的工作,这些工作会浪费资源。比如用户付了钱之后有可能不同节点会发出多封短信。
- 数据一致性:不同的机器对共享的数据进行访问,会导致数据的不一致性。而分布式锁可以实现数据的最终一致性。
- 该模型与并发模型一致,但由于在不同的机器上,因此加锁的难度较大。
- 正确性:加分布式锁同样可以避免破坏正确性的发生,如果两个节点在同一条数据上面操作,比如多个节点机器对同一个订单操作不同的流程有可能会导致该笔订单最后状态出现错误,造成损失。
分布式锁的一些特点
当我们确定了在不同节点上需要分布式锁,那么我们需要了解分布式锁到底应该有哪些特点:
- 互斥性:和我们本地锁一样互斥性是最基本,但是分布式锁需要保证在不同节点的不同线程的互斥。
- 可重入性:同一个节点上的同一个线程如果获取了锁之后那么也可以再次获取这个锁。
- 锁超时:和本地锁一样支持锁超时,防止死锁。
- 高效,高可用:加锁和解锁需要高效,同时也需要保证高可用防止分布式锁失效,可以增加降级。
- 支持阻塞和非阻塞:和ReentrantLock一样支持lock和trylock以及tryLock(long timeOut)。
- 支持公平锁和非公平锁(可选):公平锁的意思是按照请求加锁的顺序获得锁,非公平锁就相反是无序的。这个一般来说实现的比较少。
常见分布式锁
一般实现分布式锁的方式
- MySQL
- ZK
- Redis
- 自研分布式锁,谷歌的Chubby
MySQL分布式锁
InnoDB存储引擎提供了对XA事务的支持,并通过XA事务来支持对分布式事务的实现。
- 分布式事务:允许多个独立的事务资源参与到一个全局的事务中。
- 事务资源:通常是关系型数据库系统,页可以是其他类型的资源。
- 全局事务要求在其中的所有参与的事务要么都提交,要么都回滚。
实现分布式事务,InnoDB存储引擎的事务隔离级别必须为Serializable
XA事务允许不同数据库键的分布式事务,如MySQL、oracle数据库,只要参与全局事务中的每个节点都支持XA事务。
XA事务由一个或多个资源管理器、一个事务管理器以及一个应用程序组成。
- 资源管理器:提供访问事务资源的方法,通常一个数据库就是一个资源管理器
- 事务管理器:协调参与全局事务中的各个事务,需要和参与全局事务的所有资源管理器进行通信
- 应用程序:定义事务的边界,指定全局事务中的操作。
分布式事务的实现
- 采用两段式提交的方式
- 第一阶段:所有参与全局事务的节点都开始准备,告诉事务管理器它们准备好提交了
- 第二阶段:事务管理器告诉资源管理器执行ROLLBACK或COMMIT。
- 与本地事务不同的是,分布式事务要多一次prepare工作,待收到所有节点的同意信息后,再进行commit或者rollback
Java实现
Java的JTA可以很好的支持MySQL的分布式事务
1 | class MyXid implements Xid{ |
内部XA事务
- 之前的分布式事务时外部事务,即资源管理器是MySQL数据库本身
- 另一种分布式事务在存储引擎与插件间,或者存在于存储引擎与存储引擎间,称为内部XA事务。
常见的为binlog与InnoDB存储引擎间。
ZooKeeper
流程图:
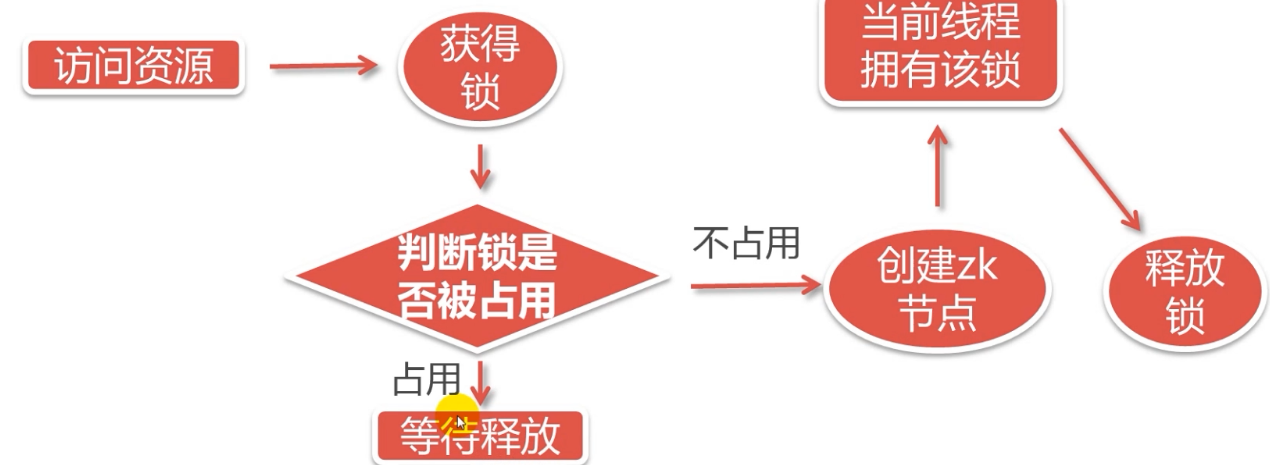
该锁是一个临时节点。
Redis
分布式锁的安全问题
上面我们介绍过红锁,但是Martin Kleppmann认为其依然不安全。有关于Martin反驳的几点,我认为其实不仅仅局限于RedLock,前面说的算法基本都有这个问题,下面我们来讨论一下这些问题:
长时间的GC pause:熟悉Java的同学肯定对GC不陌生,在GC的时候会发生STW(stop-the-world),例如CMS垃圾回收器,他会有两个阶段进行STW防止引用继续进行变化。那么有可能会出现下面图(引用至Martin反驳Redlock的文章)中这个情况:
client1获取了锁并且设置了锁的超时时间,但是client1之后出现了STW,这个STW时间比较长,导致分布式锁进行了释放,client2获取到了锁,这个时候client1恢复了锁,那么就会出现client1,2同时获取到锁,这个时候分布式锁不安全问题就出现了。这个其实不仅仅局限于RedLock,对于我们的ZK,Mysql一样的有同样的问题。
时钟发生跳跃:对于Redis服务器如果其时间发生了向跳跃,那么肯定会影响我们锁的过期时间,那么我们的锁过期时间就不是我们预期的了,也会出现client1和client2获取到同一把锁,那么也会出现不安全,这个对于Mysql也会出现。但是ZK由于没有设置过期时间,那么发生跳跃也不会受影响。
长时间的网络I/O:这个问题和我们的GC的STW很像,也就是我们这个获取了锁之后我们进行网络调用,其调用时间由可能比我们锁的过期时间都还长,那么也会出现不安全的问题,这个Mysql也会有,ZK也不会出现这个问题。
对于这三个问题,在网上包括Redis作者在内发起了很多讨论。
GC的STW
对于这个问题可以看见基本所有的都会出现问题,Martin给出了一个解法,对于ZK这种他会生成一个自增的序列,那么我们真正进行对资源操作的时候,需要判断当前序列是否是最新,有点类似于我们乐观锁。当然这个解法Redis作者进行了反驳,你既然都能生成一个自增的序列了那么你完全不需要加锁了,也就是可以按照类似于Mysql乐观锁的解法去做。
我自己认为这种解法增加了复杂性,当我们对资源操作的时候需要增加判断序列号是否是最新,无论用什么判断方法都会增加复杂度,后面会介绍谷歌的Chubby提出了一个更好的方案。
时钟发生跳跃
Martin觉得RedLock不安全很大的原因也是因为时钟的跳跃,因为锁过期强依赖于时间,但是ZK不需要依赖时间,依赖每个节点的Session。Redis作者也给出了解答:对于时间跳跃分为人为调整和NTP自动调整。
- 人为调整:人为调整影响的那么完全可以人为不调整,这个是处于可控的。
- NTP自动调整:这个可以通过一定的优化,把跳跃时间控制的可控范围内,虽然会跳跃,但是是完全可以接受的。
长时间的网络I/O
这一块不是他们讨论的重点,我自己觉得,对于这个问题的优化可以控制网络调用的超时时间,把所有网络调用的超时时间相加,那么我们锁过期时间其实应该大于这个时间,当然也可以通过优化网络调用比如串行改成并行,异步化等。可以参考我的两个文章: 并行化-你的高并发大杀器,异步化-你的高并发大杀器
Chubby的一些优化
大家搜索ZK的时候,会发现他们都写了ZK是Chubby的开源实现,Chubby内部工作原理和ZK类似。但是Chubby的定位是分布式锁和ZK有点不同。Chubby也是使用上面自增序列的方案用来解决分布式不安全的问题,但是他提供了多种校验方法:
- CheckSequencer():调用Chubby的API检查此时这个序列号是否有效。
- 访问资源服务器检查,判断当前资源服务器最新的序列号和我们的序列号的大小。
- lock-delay:为了防止我们校验的逻辑入侵我们的资源服务器,其提供了一种方法当客户端失联的时候,并不会立即释放锁,而是在一定的时间内(默认1min)阻止其他客户端拿去这个锁,那么也就是给予了一定的buffer等待STW恢复,而我们的GC的STW时间如果比1min还长那么你应该检查你的程序,而不是怀疑你的分布式锁了。