Map
Map代表一种映射关系,其指这个key与它的value存在某种相关的联系。
- 当这个Key与一个概念存在某种抽象的联系时,就需要使用Map。
前言
符号表(Symbol Table)是一种存储键值对的数据结构,可以支持快速查找操作。
符号表分为有序和无序两种,有序符号表主要指支持min()、max()等根据键的大小关系来实现的操作。
有序符号表的键需要实现Comparable接口。
1 | public interface UnorderedST<Key, Value> { |
初级实现
链表实现无序符号表
1 | public class ListUnorderedST<Key, Value> implements UnorderedST<Key, Value> { |
二分查找实现有序符号表
使用一对平行数组,一个存储键一个存储值。
二分查找的rank()方法至关重要,当键在表中时,它能够知道该键的位置;当键不在表中时,它也能知道在何处插入新键。
二分查找最多需要logN + 1次比较,使用二分查找实现的符号表的查找操作所需要的时间最多是对数级别的。但是插入操作需要移动数组元素,是线性级别的。
1 | public class BinarySearchOrderedST<Key extends Comparable<Key>, Value> implements OrderedST<Key, Value> { |
HashMap
散列表类似于数组,可以把散列表的散列值看成数组的索引值。访问散列表和访问数组元素一样快速,它可以在常数时间内实现查找和插入操作。
由于无法通过散列值知道键的大小关系,因此散列表无法实现有序性操作。
散列函数
对于一个大小为M的散列表,散列函数能够把任意键转换为[0, M-1]内的正整数,该正整数即为hash值。
散列表存在冲突,也就是两个不同的键可能有相同的hash值。
散列函数应该满足以下三个条件:
- 一致性:相等的键应当有相等的hash值,两个键相等表示调用
equals()返回的值相等。 - 高效性:计算应当简便,有必要的话可以把hash值缓存起来,在调用hash函数时直接返回。
- 均匀性:所有键的hash值应当均匀地分布到[0, M-1]之间,如果不能满足这个条件,有可能产生很多冲突,从而导致散列表的性能下降。
除留余数法
讲所有的数据类型以某种规则转换到一个整数。
除留余数法可以将整数散列到[0, M-1]之间,例如一个正整数 k,计算k%M既可得到一个[0, M-1]之间的hash值。注意M最好是一个素数,否则无法利用键包含的所有信息。例如M为 10k,那么只能利用键的后k位。
对于其它数,可以将其转换成整数的形式,然后利用除留余数法。例如对于浮点数,可以将其的二进制形式转换成整数。
对于多部分组合的类型,每个部分都需要计算 hash 值,这些 hash 值都具有同等重要的地位。为了达到这个目的,可以将该类型看成 R 进制的整数,每个部分都具有不同的权值。
例如,字符串的散列函数实现如下:
1 | int hash = 0; |
再比如,拥有多个成员的自定义类的哈希函数如下:
1 | int hash = (((day * R + month) % M) * R + year) % M; |
R通常取31。
Java 中的hashCode()实现了哈希函数,但是默认使用对象的内存地址值。在使用hashCode()时,应当结合除留余数法来使用。因为内存地址是32位整数,我们只需要31位的非负整数,因此应当屏蔽符号位之后再使用除留余数法。
1 | int hash = (x.hashCode() & 0x7fffffff) % M; |
使用Java的HashMap等自带的哈希表实现时,只需要去实现Key类型的hashCode()函数即可。Java规定hashCode()能够将键均匀分布于所有的32位整数,Java中的String、Integer 等对象的hashCode()都能实现这一点。以下展示了自定义类型如何实现hashCode():
1 | public class Transaction { |
hashCode
Java的hashCode是int类型的,即拥有符号。
哈希冲突
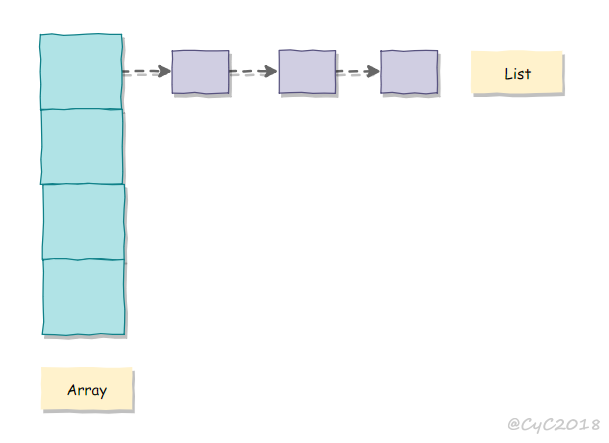
拉链法
拉链法使用链表来存储hash值相同的键,从而解决冲突。
查找需要分两步,首先查找Key所在的链表,然后在链表中顺序查找。
对于N个键,M条链表(N>M),如果哈希函数能够满足均匀性的条件,每条链表的大小趋向于N/M,因此未命中的查找和插入操作所需要的比较次数为~N/M。
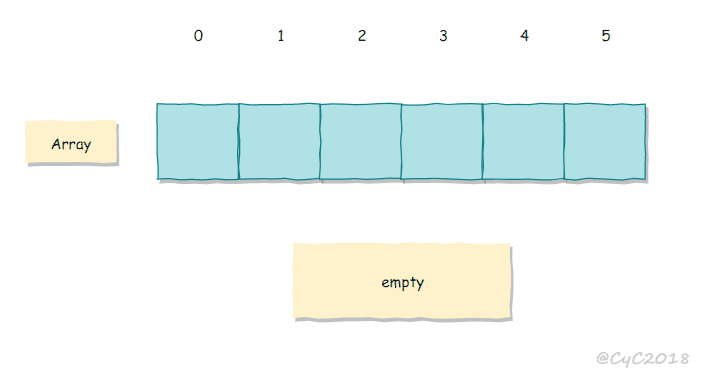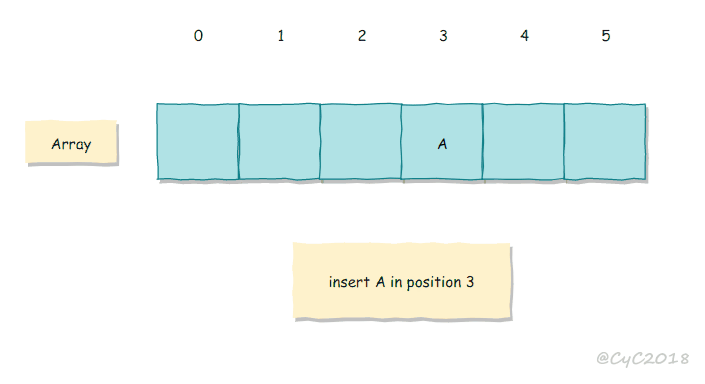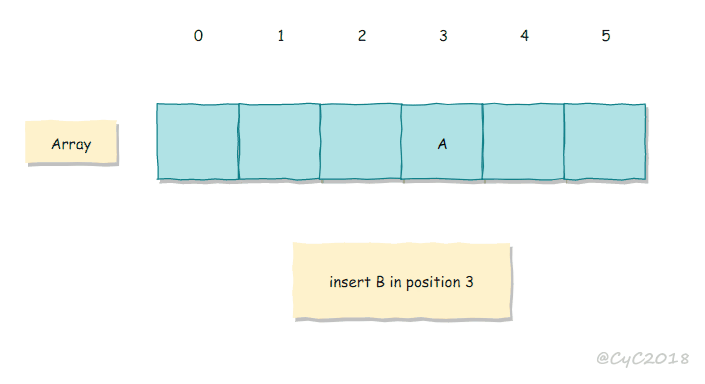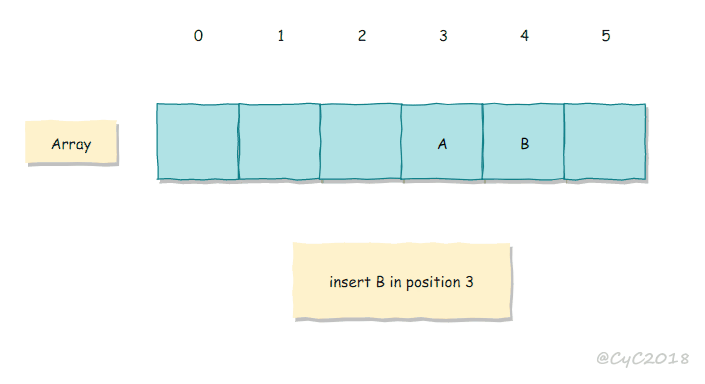
线性探测法
线性探测法使用空位来解决冲突,当冲突发生时,向前探测一个空位来存储冲突的键。
使用线性探测法,数组的大小 M 应当大于键的个数 N(M>N)。
1 | public class LinearProbingHashST<Key, Value> implements UnorderedST<Key, Value> { |
查找
1 | public Value get(Key key) { |
插入
1 | public void put(Key key, Value value) { |
删除
删除操作应当将右侧所有相邻的键值对重新插入散列表中。
1 | public void delete(Key key) { |
调整数组大小
线性探测法的成本取决于连续条目的长度,连续条目也叫聚簇。当聚簇很长时,在查找和插入时也需要进行很多次探测。例如下图中 2~5 位置就是一个聚簇。
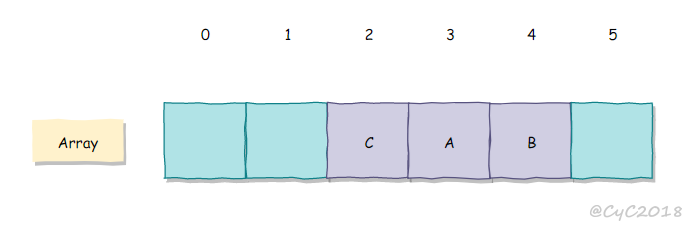
α = N/M,把α称为使用率。理论证明,当α小于1/2时探测的预计次数只在1.5到2.5之间。为了保证散列表的性能,应当调整数组的大小,使得α在[1/4, 1/2]之间。
1 | private void resize() { |
再哈希法
当一个哈希函数产生了哈希冲突后,再用另外一个哈希方法再次进行哈希索引。
小结
符号表算法比较
| 算法 | 插入 | 查找 | 是否有序 |
|---|---|---|---|
| 链表实现的无序符号表 | N | N | yes |
| 二分查找实现的有序符号表 | N | logN | yes |
| 二叉查找树 | logN | logN | yes |
| 2-3 查找树 | logN | logN | yes |
| 拉链法实现的散列表 | N/M | N/M | no |
| 线性探测法实现的散列表 | 1 | 1 | no |
应当优先考虑散列表,当需要有序性操作时使用红黑树。
Java 的符号表实现
- java.util.TreeMap:红黑树。
- java.util.HashMap:拉链法的散列表。
稀疏向量乘法
当向量为稀疏向量时,可以使用符号表来存储向量中的非 0 索引和值,使得乘法运算只需要对那些非0元素进行即可。
1 | public class SparseVector { |