Redis
起源:为了实现一个访客信息追踪网站,展示网站最近的n条访问记录。而当时数据库在负载高时无法很好满足。
概述
- 高性能Key-Value服务器。分布式内存key-value的数据库。
- 多种数据结构。
- 丰富的功能。慢查询、发布订阅等
- 高可用分布式支持。
Redis具有复制特性扩展读性能,使用分片扩展写性能,可以持久化到硬盘,支持主从备份,所有操作都是原子性的,支持合并多个操作为原子性。
应用
适用性
- 取单个最新数据的操作。
- 排行榜类似应用。
- 精准设定过期时间。
- 实时系统、垃圾系统、实时消息系统、队列系统。
- 唯一性检查应用。
缺陷
- 由于阉割了数据表、字段等特性,所有查询都依赖于Key,Redis无法提供常规数据库所具备的多列查询、区段查询等复杂查询功能。
- Redis需要把数据存在内存中,这也大大限制了Redis可存储的数据量,这也决定了Redis难以用在数据规模很大的应用场景中。
配置
- daemonize:是否为守护进程,如果为yes会将日志打印到文件当中。
- port:对外端口,6379。
- logfile:系统日志。
- dir:Redis工作目录。
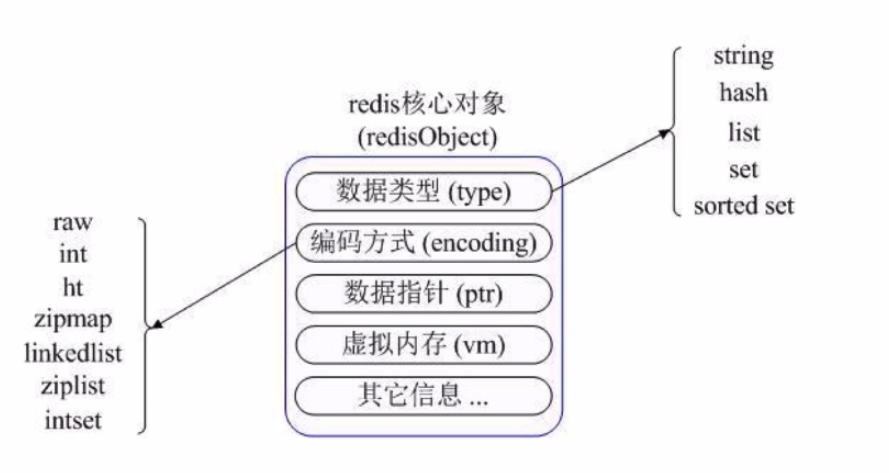
数据结构与对象
Redis数据库里面的每个键值对都是由对象组成的
- 数据库键总是一个字符串对象。
- 数据库键的值可以是:
- 字符串对象。
- 列表对象。
- 哈希对象。
- 集合对象(set)。
- 有序集合对象。
命令
set
Redis将在数据库创建一个新的键值对,键值为msg,值为helloworld。
1 | set msg "helloworld" |
rpush
将创建一个列表对象,key为fruits,value为列表。
1 | rpush fruits "apple" "banana" "cherry" |
高并发场景下缓存常见问题
- 缓存一致性:
- 当数据时效要求很高,要保证缓存中的数据与数据库中的数据保持一致。并且缓存结点与副本中的数据也保持一致。
- 依赖缓存的过期与更新策略。在数据发生更改时,主动更改缓存中的数据,或移除对应的缓存:
- 更新数据库成功,更新缓存失败,数据不一致。
- 更新缓存成功,更新数据库失败,数据不一致。
- 更新数据库成功,淘汰缓存失败,数据不一致。
- 淘汰缓存成功,更新数据库失败,查询缓存miss。
- 缓存并发问题:
- 缓存过期后,将尝试从后端数据库获取数据。在高并发下,可能多个请求同时向数据库请求获取。
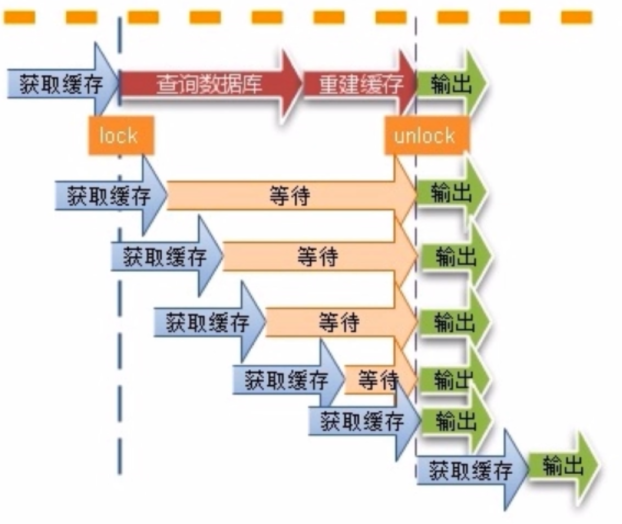
- 缓存穿透问题:
- 某个key在高并发的访问下没有被命中,出于容错率的情况,尝试去后端数据库中获取,导致大量的请求到达数据库本身。当该key对应的数据本身为空,就会导致数据库中并发执行很多不必要的操作。
- 缓存空对象,对查询结果为空的对象也进行缓存。
- 缓存的雪崩现象:
- 缓存抖动(颠簸),缓存结点故障,通过一致性哈希算法解决。
- 由于缓存的原因,导致大量请求到达后端数据库,导致数据库崩溃,系统崩溃。
- 可能由于缓存抖动、缓存并发、或者部分缓存集体失效过期导致。
- 通过限流、降级、熔断手段降低影响,通过多级缓存。
Redis原理
单线程
可以想为Redis的所有命令都在一个阻塞队列当中,每一个瞬间只会执行一个命令。
原因:
- 纯内存,内存是1000W/s。
- 非阻塞IO,并使用epoll作为IO多路复用的一个是实现,并Redis自身实现了一个事件处理,将epoll的连接、读写、关闭转化为自身的一个事件,不在IO上花费太多的时间。
- 避免线程切换和竞态消耗。
事件循环
Redis服务在启动后会陷入一个巨大的while循环,不停处理文件事件和时间事件。
所有的事件都存在于一个队列当中。
- 文件事件:在多个客户端实现多路复用,文件事件在一个有序队列当中,其排列规则是文件事件建立的规则。
- 时间事件:记录那些要在指定事件点运行的事件,多个事件事件以无序链表的形式存放在服务器状态中。
- Redis自身的任务。
- 更新服务器的各类统计信息,如时间、内存占用等。
- 数据库后台操作,key过期清理,数据库rehash等。
- 关闭、清理失效的客户端连接。
- 检查是否需要RDB dump,AOF重写。
- 主节点、对从节点定期同步。
- 集群模式,集群定期同步信息。
流程:
- beforeSleep
- epollwait
- 处理请求,即文件事件。
- 定时时间。
逐出
当执行write单内存达到上限时,强制将一些key删除。逐出策略有:
- allkeys:所有key。
- volatile:设置了过期的key。
- LRU。
- random。
- ttl:最快过期的。
特点
- 不是精确算法,而是抽样对比。
- 每次写入操作前判断。
- 逐出时阻塞请求的。
逐出的QPS过高会影响正常请求。
延迟删除
为什么要用
cache与db数据不一致问题。
产生原因:请求回源时,由于DB主从延迟导致用DB从节点的老数据更新了cache。
解决方案:cache延迟多次删除,当前删除一次,过几秒(大于DB主从延迟)后再次删除一次。
概述
读取操作:先redis,redis没有就读db。
写操作:
- 先更新redis再更新db。
- 先更新db再更新redis。
- 先更新DB再删除redis。
- 先删除redis再更新DB。
- 延迟双删。
- 延迟删除等变种。
非一致性
先更新redis再更新db。AB为两个线程,则此时db最终为a值,但redis为b值:
- A_update_redis。
- B_update_redis。
- B_update_db。
- A_update_db。
先更新db再更新redis。最终db是b值但是redis是a值:
- A_update_db。
- B_update_db。
- B_update_redis。
- A_update_redis。
先更新DB再删除redis。
- A_update_db。
- B_update_db。
- B_rm_redis。
- A_rm_redis。
不一致的原因为:
- A_get_data。
- redis_cache_miss。
- A_get_db。
- B_update_db。
- B_rm_redis。(此时如果拿db是b值,但是redis没有值)。
- A_update_redis。
依赖于A_update_redis在B_update_db之后,极端情况此时redis是old,db是new。
先删除redis再更新DB。此时redis是old值,db是new值
- A_rm_redis。
- B_get_data。
- B_redis_miss。
- B_get_db。
- B_update_redis。
- A_update_db。
最终一致性
延迟双删。最后一次sleep一段时间再rm_redis保证再次读请求回溯打到db,用最新值写redis。
- rm_redis。
- update_db。
- sleep xxx ms。
- rm_redis。
变种。解决了3中的极端情况(靠sleep解决),并且减少5中第一次不必要的rm redis请求。当然,这个rm_redis还可以考虑异步化(提高吞吐)以及重试(避免异步处理失败)。
- update_db。
- sleep xxx ms。
- rm_redis。
Sentinel
优化
- 拒绝长(慢)命令。keys、flushshall、slow lua script。
- 其实不是单线程,在AOF等是给另一个线程去做,它会fysnc file descriptor。
单机数据库的实现
- 数据库:
- Redis数据库的实现原理。
- 说明了服务器保存键值对的方法。
- 服务器保存键值对过期时间的方法。
- 服务器自动删除过期键值对的方法。
- RDB持久化、AOF持久化:
- Redis两种持久化方法的实现原理。
- 服务器根据数据库来生成持久化文件的方法。
- 服务器根据持久化文件还原数据库的方法。
- BGSAVE与BGREWAITEAOF的实现原理。
- 事件:
- 文件事件:
- 应答客户端连接请求。
- 接收客户端发送的命令请求。
- 向客户端返回命令回复。
- 时间事件:
- 执行redis.c/serverCron函数,通过执行常规的维护和管理操作保持Redis服务器的正常运作。
- 触发一些定时操作。
- 文件事件:
- 客户端。
- 服务器。
缓存使用
如何利用有限的资源提供尽可能大的吞吐量。
请求直接从缓存中获取数据,直接返回。
缓存特征
- 命中率:命中数/(命中数+没有命中数):
- 没有命中,缓存过期,需要从数据库当中重新获取。
- 影响因素:
- 业务场景和业务需求:读多写少,实时性要求越低。
- 缓存的设计(粒度和策略):粒度越小,命中率越高。如果缓存一个对象与一个组的对象,一个对象的命中率更高。缓存策略,即缓存的更新。
- 缓存容量和基础设施:多数采用LRU算法。
- 并发越高,即使过期时间很短,缓存收益也很高。
- 当缓存结点出现故障,需要避免缓存失效,并最大程度降低影响。
- 最大元素(空间):缓存中可以存放的最大数量。
- 清空策略:FIFO、LFU、LRU,过期时间、随机等。
缓存命中率影响因素
业务场景和业务需求:
- 业务场景:缓存适合读多写少的场景。
- 业务需求:决定对实时性的要求,直接影响缓存的更新策略与更新时间,实时性要求越低就越适合缓存。
缓存的设计(粒度和策略):
缓存的粒度越小,命中率越高。如果只缓存一个用户信息,此时当用户更新才需要更新缓存;如果缓存了一个集合,则集合当中任一个值更新都要更新缓存。
当数据发生变化时,更新缓存的值比移除缓存或缓存更新的命中率更高。
缓存容量和基础设施:
- 缓存容量有限,则容易导致缓存被淘汰,多数缓存使用LRU。
- 使用本地缓存容易出现单机瓶颈,分布式缓存更容易扩展。
- 不同的缓存框架的效率与稳定性各不相同。
缓存节点故障需要避免缓存失效并最大程度降低影响:
- 通过一致性哈希或节点冗余方式。
并发越高,缓存受益越高。
缓存设计
- 尽可能地通过缓存获取数据,并避免缓存失效:
- 需要从业务需求、缓存粒度、缓存策略、技术选型等各方面进行权衡,需要聚焦在高频访问且时效性要求不高的热点业务上。
- 通过缓存预热、增加缓存容量、调整缓存粒度、更新缓存等手段来提高命中率。
缓存分类和应用场景
根据缓存与应用的耦合度:
- 本地缓存:
- 编程实现,成员变量、局部变量、静态变量。
- Guava Cache。设计灵感来自于ConcurrentHashMap。
- 无法共享。
- 分布式缓存。自身是一个独立的应用,与应用程序隔离。
- Memcache。本身不提供分布式解决方案,分布式通过客户端实现路由实现分布式。
- Redis。
Memcache
在服务端,Memcache的集群环境就是服务器节点的堆积。
通过一致性hash算法实现路由,除了计算key的哈希值还会计算每一个对应Server的哈希值,然后将哈希值映射到一个有限的值域中。
通过寻找server hash>key hash的最小server作为目标server,如果找不到,则直接将最小hash值的server作为目标server,增加或删除单个节点对于集群不会有大的影响。
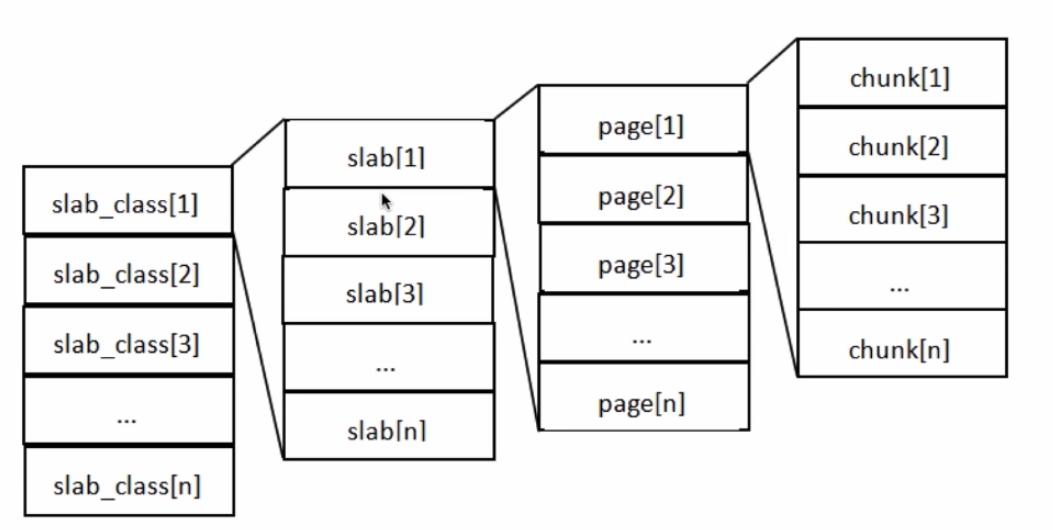
内存结构图
- stab_class:
- stab:Memcache将内存空间分为了一组stab,有相同大小的chunk被组织为一个stab。LRU针对stab而不是整体
- page:每个stab拥有一组page,申请内存以page为单位。page大小1M,不会有1M大小的value,不会有256字节的key。
- chunk:chunk是存放数据的地方,一组chunk大小是一样的。
- value总会被存放在与chunk大小最接近的地方。即总会有内存浪费
Memcache不能遍历它内部的item。
高性能:
- 一致性哈希找到server。
- 通过hash算法找到item。
Memcache是一个非阻塞的基于事件的服务器程序,