并发
为什么要用
从OS的角度讲,多线程处理在OS当中几乎已经时一项必备的功能了,让计算机同时去做几件事情。
- 因为计算机的运算能力强大。而且还因为计算机的运算速度与它的存储、通信子系统速度差距太大,大量时间花费在磁盘IO、网络通信或数据库访问上。而我们不希望将CPU大部分时间都处于等待其他资源的时间上。
- 一个服务端同时对多个客户端提供服务是另一个更具体地并发应用场景。
从开发的角度讲,线程使得复杂的异步代码变得简单,极大地简化了复杂系统地开发。
并发、高并发相关概念
并发:同时拥有两个或多个线程,如果程序在单核处理器上运行,多个线程将交替地还如或者换出内存,线程同时存在, 每个线程都处于执行过程中的某个状态,如果运行在多核处理器上,程序的每个线程都将分配到一个处理器核上,因此可以同时运行。
高并发:通过设计保证系统能够同时并行处理很多请求。
多线程
线程将复杂、异步的代码转换为更直接、直观的代码,线程是控制和利用多CPU系统计算能力的最简单方式。
异步:当烧水的时候,水还在烧,这个时候水是否烧开了引起关注,在任务结束的时候发出信号,一边做其他的事情。
多线程将异步操作转换为了顺序,同步的代码。
多线程的特点
优势:
- 发挥多处理的强大能力:同时处理多个请求,响应快,复杂操作可以分为多个线程程同时执行。
- 充分利用多个CPU的计算资源。在如果设计正确,多线程程序可以通过提高CPU资源的利用率来提升系统吞吐率。
- 即使单CPU下,提高处理器的资源利用率来提升系统吞吐率。CPU在等待IO时可以做其他的事情。在IO时候,进程在读取文件,CPU在等待文件,因此CPU的资源浪费了,而利用多线程,可以使得在读取第二个文件的时候,处理第一个文件。
- 建模的简单性:在某些情况更简单,将异步的代码转换为顺序的代码,容易维护,更好地模拟人类的工作方式:
- 在单线程上进行文件读取与处理,则必须跟踪每个文件的读取与处理状态。多线程下,可以启动两个线程,每个线程只读取和处理单个文件。
- 如果在程序中只包含一种类型的任务,比包含多种不同类型任务的程序要更易于编写。使用线程可以讲复杂且异步的工作流进一步分解为一组简单且同步的工作流,每个工作流在一个单独的线程中运行,并在特定的同步位置交互。
- 例如Servlet的开发人员不需要了解有多少请求在同一时刻要被处理,也不需要理解套接字的输入流或输出流是否被阻塞,当调用Servlet的service方法响应请求时,可以用同步方式来处理这给请求,就好像它是应该单线程程序。
- 异步事件的简化处理:
- 服务器应用程序在接受多个远程客户端的套接字连接请求时,如果为每个连接都分配各自的线程并且使用同步IO,就会降低这类程序的开发难度。
- 对于单线程,如果套接字没有数据到来,读操作将一直堵塞,为了避免该问题,单线程需要使用非阻塞IO(java.nio),而这种IO复杂性远高于同步IO,并且容易出错。而使用多线程则该请求的阻塞不会影响其他请求的处理。
- 响应更灵敏的用户界面。
成本:
- 安全性问题:
- 访问共享数据的多个线程执行的代码需要特别注意,没有充分同步情况下,多线程的操作执行顺序时不可预测的。线程交互远非简单。错误的线程同步引起的错误很难检测,重现和修复。
- 上下文切换开销:
- 当CPU从执行一个线程切换到执行另一个线程时,CPU需要保存当前线程的本地数据,程序指针等,并加载下一个线程的本地数据,程序指针等来执行。
- 上下文切换过程中丢失局部性,并将CPU时间更多的花在线程调度而不是运行上。并且同步机制往往抑制某些编译器优化,使得内存缓冲区中数据无效,增加共享内存总线的同步流量。
- 资源消耗增加:
- 线程需要来自计算机的一些资源才能运行。除了CPU时间,线程需要一些内存来保持其本地堆栈。它还可能占用管理线程所需的操作系统内部的一些资源。
- 如何选择正确的线程数。
风险:
- 安全性:多个线程共享数据可能会产生与预期不相符的结果:
- 一个简单的next++分为三步:读取,++,写入新值。由于线程之间可能交替占有运行时,因此可能报错。它取决于运行时如何交替进行这些操作。
- 同步机制:将方法声明为synchronized可以修正该问题。
- 活跃性:某个操作无法继续执行下去,线程会导致一些在单线程程序中不会出现的问题,例如死锁、饥饿、活锁等。它们依赖于不同线程的事件发生时序,在开发或测试中并不总是能够重现。
- 性能:线程过多使得CPU频繁切换(上下文切换),调度时间增多;同步机制;消耗过多内存。
实际场景
对于RMI调用。RMI使得代码能够调用在其他JVM中运行的对象, 但是当RMI调用远程对象时,这个调用将在哪个线程中执行,但一定不是我们创建的线程,而RMI会创建多少个线程,同应该远程对象上的同一个远程方法会不会在多个RMI线程中被同时调用。
远程 对象必须注意两个线程安全性问题:正确地协同在多个对象中共享的状态,以及对远程对象本身状态的访问,RMI对象需要做好被多个线程同时调用的准备。
线程状态
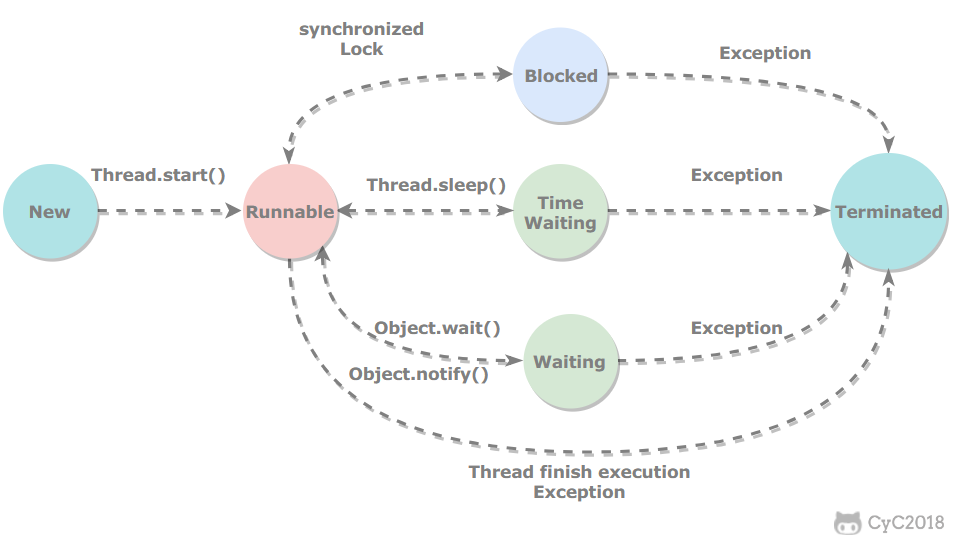
新建(New)
创建后尚未启动。
可运行(Runnable)
可能正在运行,也可能正在等待 CPU 时间片。
包含了操作系统线程状态中的 Running 和 Ready。
阻塞(Blocking)
等待获取一个排它锁,如果其线程释放了锁就会结束此状态。
无限期等待(Waiting)
等待其它线程显式地唤醒,否则不会被分配 CPU 时间片。
| 进入方法 | 退出方法 |
|---|---|
| 没有设置Timeout参数的Object.wait()方法 | Object.notify()/Object.notifyAll() |
| 没有设置Timeout参数的Thread.join()方法 | 被调用的线程执行完毕 |
| LockSupport.park()方法 | LockSupport.unpark(Thread) |
限期等待(Timed Waiting)
无需等待其它线程显式地唤醒,在一定时间之后会被系统自动唤醒。
调用Thread.sleep()方法使线程进入限期等待状态时,常常用“使一个线程睡眠”进行描述。
调用Object.wait()方法使线程进入限期等待或者无限期等待时,常常用“挂起一个线程”进行描述。
睡眠和挂起是用来描述行为,而阻塞和等待用来描述状态。
阻塞和等待的区别在于,阻塞是被动的,它是在等待获取一个排它锁。而等待是主动的,通过调用Thread.sleep()和Object.wait()等方法进入。
| 进入方法 | 退出方法 |
|---|---|
| Thread.sleep()方法 | 时间结束 |
| 设置了Timeout参数的Object.wait()方法 | 时间结束Object.notify()/Object.notifyAll() |
| 设置了Timeout参数的Thread.join()方法 | 时间结束/被调用的线程执行完毕 |
| LockSupport.parkNanos()方法 | LockSupport.unpark(Thread) |
| LockSupport.parkUntil()方法 | LockSupport.unpark(Thread) |
死亡(Terminated)
可以是线程结束任务之后自己结束,或者产生了异常而结束。
如何设计解决并发问题
具体思想
编写线程安全的代码,核心在于对状态访问操作进行管理,特别时对共享的和可边的状态的访问。而对象的状态包含了任何可能影响其外部可见行为的数据,其是指存储在实例或者静态域当中的数据,并且可能包括其他依赖对象的域,例如Map中的Entity。
一个对象是否线程安全取决于它是否被多个线程访问。并且至少有一个线程是执行写入操作的。
手段
- 不在线程间共享该状态变量。
- 将状态变量修改为不可变的变量。
- 在访问状态变量时使用同步。
使用同步
- 设计线程相对安全的类:
- 在调用线程相对安全的类时,额外进行相关的安全访问。或者防止在调用方进行线程不安全的操作。
- 尽可能使用现有的线程安全对象(Atomic)来管理类的状态,相比于非线程安全的对象,判断线程安全对象的可能状态及其状态转换情况更为容易,也更容易维护和验证线程安全性。
并发及并发的线程安全处理:
- 多线程并发编程:
- 线程安全性:
- 原子性、可见性、有序性。
- atomic包。
- CAS算法。
- synchronize与Lock、volatile、happes-before。
- 安全发布对象:
- 安全发布方法。
- 不可变对象、final关键字的使用、不可变方法。
- 线程不安全类与写法。
- 线程封闭、同步容器、并发容器:
- 堆栈封闭。
- ThreadLocal线程封闭、JDBC的线程封闭。
- 同步容器、并发容器。
- J.U.C。
- AQS等J.U.C组件。
- - 线程调度:
- 线程池好处。
- new Thread弊端。
- ThreadPoolExecutor、Executor框架接口。
- 线程安全补充内容:
- 死锁产生于预防。
- 多线程并发的最佳实践。
- spring的线程安全。
- hashmap与concurrentHashMap。
- 线程安全性:
硬件知识
硬件的效率与一致性
让计算机并发执行若干个运算任务与更充分地利用计算机处理器地效能间地因果关系,看似顺理成章,其实关系比较复杂。
其中一个原因是绝大多数地运算任务都不可能只靠处CPU计算就能完成,CPU至少需要与内存交互,读取运算数据、存储运算结果。而这个IO操作很难消除。
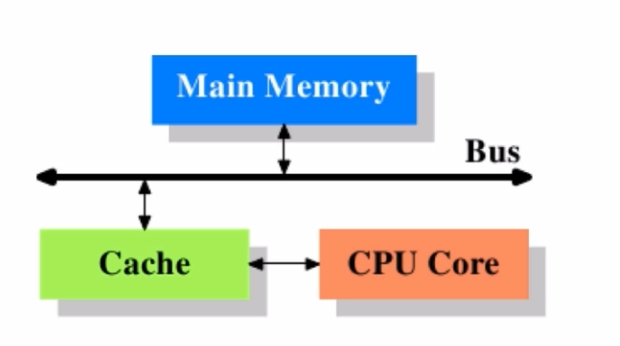
由于计算机地存储设备与CPU运算速度有几个数量级地差距,很多现代OS不得不加入一层速度尽可能接近处理器运算速度的高速缓存。
高速缓存很好地解决了速度矛盾,但带来了另外一个问题。即缓存一致性。每个CPU都有自己地高速缓存,而它们又共享同一主内存。则当多个CPU都涉及同一块主内存区域时,将可能导致各自地缓存数据不一致。因此出现了缓存一致性协议,包括有MESI、MSI、Synapse等。
除了针对内存等,为了使得CPU内部的运算单元能够被充分利用,CPU可能会对输入代码进行乱序执行优化,CPU会在计算后将乱序执行的结果重组,保证该结果与顺序执行的结果一致,但不保证程序中每个语句的计算的先后顺序与代码中一致。
CPU多级缓存
高速缓存的配置:数据的读取与存储都经过高速缓存,CPU核心与高速缓存有一条快速通道。主存与高速缓存都连接在系统总线上,并且该主线还用于与其他通信。
多级缓存:一级缓存的速度与主存速度拉大。加入二级缓存、三级缓存,速度慢于1级,但是更大。
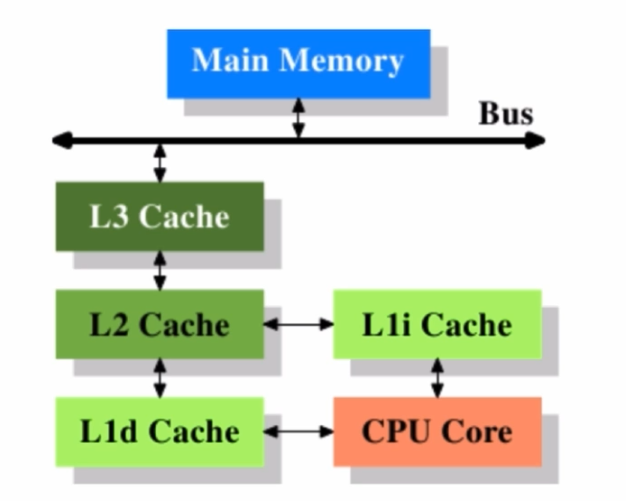
多级缓存的意义
- CPU的频率太快,主存无法跟上,在处理器时钟周期内,CPU常常需要等待主存,浪费资源。缓存是为了缓解CPU与内存间速度不匹配的问题。
- 缓存无法存放CPU需要的全部数据,但是由于:
- 时间局部性:如果某个数据被访问,那么在不久的将来可能再次被访问。
- 空间局部性:如果某个数据被访问,那么与它相邻的数据很快也可能被访问。
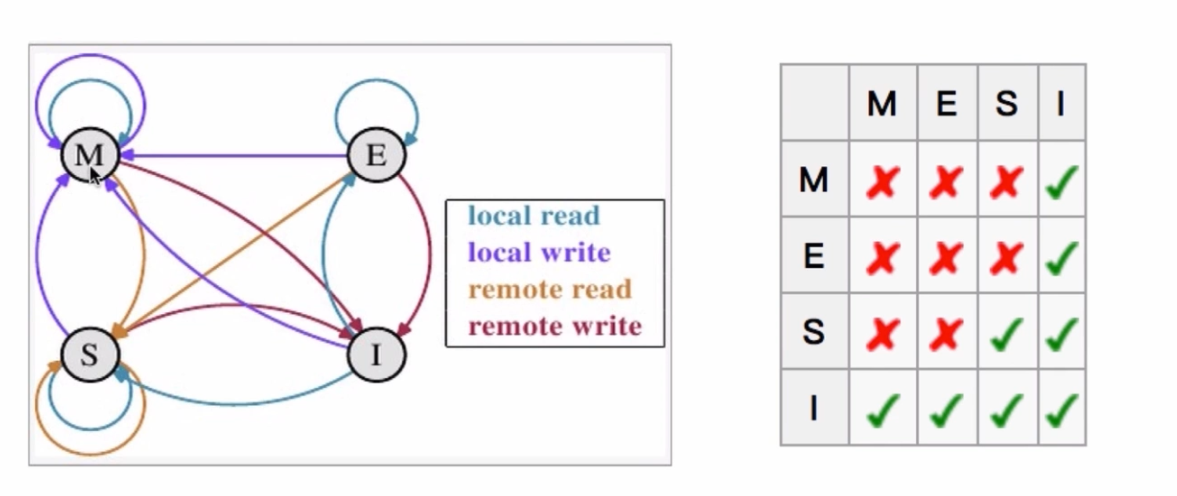
缓存一致性(MESI协议)
利用CPU的嗅探总线实现。
用于保证多个CPU 缓存之间共享数据的一致,定义了cache的四种状态:
- M:被修改,该缓存只缓存在CPU的缓存中,并且被修改过,与主存数据不一致,需要在某个时间写回主存(这个时间其他CPU不能读取该数据),被写会主存当中后转换为E。
- E:独享,只缓存在CPU缓存中,但是没有被修改,与主存数据一致,当其他CPU读取该数据,转换为S,当修改该数据则转换为M。
- S:共享,该缓存可能被多个CPU共享,并与主存一致,如果有一个CPU修改该缓存,则转换为M。其他CPU的缓存转换为I。
- I:无效。
操作:
- local read:读本地缓存数据。
- local write:将数据写入本地缓存。
- remote read:将主存数据读取过来。
- remote write:将数据写入主存。
乱序执行优化
处理器为提高运算速度而做出违背代码原有顺序的优化。在不影响结果的情况下,代码的执行次序可能会发生变化。
在多核CPU中,后写入缓存的数据未必真的写入缓存。
多线程并发最佳实践
- 尽量使用本地变量。
- 使用不可变类。
- 最小化锁的作用域范围。
- 使用线程池的executor,而不是newThread。
- 宁可使用同步也不要使用现场的wait和notify。
- 使用blockingQueue实现生产-消费模式。
- 使用并发集合而不是加了锁的同步集合。
- 使用semaphore创建有界的访问。
- 宁可使用同步代码块,也不使用同步的方法。
- 避免使用静态变量。
并发模拟
- postman:http请求模拟。
- Apache bench:测试网站性能。
- JMeter:压力测试工具。
- 代码:semaphore信号量、CountDownLatch计数器。通常与线程池共同使用。
并发模型
并发模型与分布式系统相似性
在并发系统中,不同的线程彼此通信。在分布式系统中,不同的进程彼此通信(可能在不同的计算机上)。
模型
一个顺序处理相同类型问题的程序更加简单,更少出错,容易测试。如果处理多种类型的问题, 则需要考虑优先级,时间截止等,较为复杂。
因此,为每一个相同类型任务的程序提供一个线程,提供理想上的顺序,并且将域逻辑与时序调度的细节分割开,进行相互交替的操作,只有在特定的同步点进行彼此间的交互。
并行工人
传入的工作分配给不同的工作人员。这是一个说明并行工作者并发模型的图表:

在并行工作者并发模型中,委托者将传入的作业分发给不同的工作者。每个工人完成整个工作。这些工作程序并行工作,在不同的线程中运行,并且可能在不同的CPU上运行。是Java应用程序中最常用的并发模型(虽然这种情况正在发生变化)。
优劣
- 易于理解。要增加应用程序的并行化,您只需添加更多工作程序。
- 共享可能变得复杂。
参考
- java并发编程入门与高并发解决方案
- 慕课网《Java并发编程入门与高并发面试 》课程学习