海量数据排序
外部排序
传统的排序算法一般指内排序算法,针对的是数据可以一次全部载入内存中的情况。但是面对海量数据,即数据不可能一次全部载入内存,需要用到外排序的方法。外排序采用分块的方法(分而治之),首先将数据分块,对块内数据按选择一种高效的内排序策略进行排序。然后采用归并排序的思想对于所有的块进行排序,得到所有数据的一个有序序列。
例如,考虑一个1G文件,可用内存100M的排序方法。
- 首先将文件分成10个100M,并依次载入内存中进行排序,最后结果存入硬盘。得到的是10个分别排序的文件。
- 接着从每个文件载入9M的数据到输入缓存区,输出缓存区大小为10M。对输入缓存区的数据进行归并排序,输出缓存区写满之后写在硬盘上,缓存区清空继续写接下来的数据。
- 对于输入缓存区,当一个块的9M数据全部使用完,载入该块接下来的9M数据,一直到所有的9个块的所有数据都已经被载入到内存中被处理过。最后我们得到的是一个1G的排序好的存在硬盘上的文件。
继续优化
- 磁盘I/O通常是越少越好(最好完全没有),那么如何降低磁盘I/O操作呢?关键就在第5和第6步中的40路输入缓冲区,我们可以先做8路merge sort,把每8个块合并为1路,然后再做5-to-1的合并操作。
- 再深入思考一下,如果有多余的硬件,如何继续优化呢?有三个方向可以考虑:
- 使用并发:如多磁盘(并发I/O提高)、多线程、使用异步I/O、使用多台主机集群计算。
- 提升硬件性能:如更大内存、更高RPM的磁盘、升级为SSD、Flash、使用更多核的CPU。
- 提高软件性能:比如采用radix sort、压缩文件(提高I/O效率)等。
在1000000个元素中选出前100名。
在N个元素选出前M个元素。在1000000个元素选出前100名。
- 优先队列,维护当前看到的前M个元素。
TOP K
问题描述:
TopK Elements 问题用于找出一组数中最大的 K 个的数。
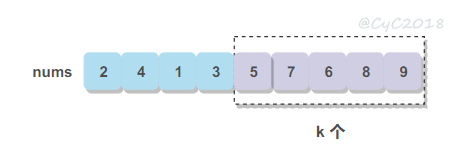
此外还有一种叫 Kth Element 问题,用于找出一组数中第 K 大的数。
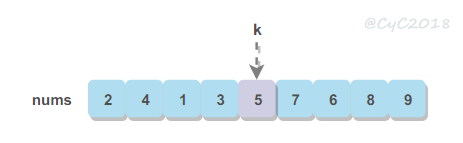
如果要找的 TopK Elements 是最小的 K 个数,那么可以将问题转换成求解 TopK Elements,因为找到 Kth Element 之后,再遍历一遍,小于等于 Kth Element 的数都是 TopK Elements。
堆排序
可针对海量数据
为了查找Top k大的数,我们可以使用大根堆来存储最大的K个元素。大根堆的堆顶元素就是最大K个数中最小的一个。每次考虑下一个数x时,如果x比堆顶元素小,则不需要改变原来的堆。如果想x比堆顶元素大,那么用x替换堆顶元素, 同时,在替换之后,x可能破坏最小堆的结构,需要调整堆来维持堆的性质。算法实现如下:
1 | public static int[] findTopK(int[] array, int k) { |
快排
虽然我们不会采用快速排序的算法来实现TOP-K问题,但我们可以利用快速排序的思想,在数组中随机找一个元素key,将数组分成两部分Sa和Sb,其中Sa的元素>=key,Sb的元素<key,然后分析两种情况:
- 若Sa中元素的个数大于或等于k,则在Sa中查找最大的k个数
- 若Sa中元素的个数小于k,其个数为len,则在Sb中查找k-len个数字
如此递归下去,不断把问题分解为更小的问题,直到求出结果。
该算法的平均时间复杂度为O(N * logk)。以求K大的数为例,算法实现如下:
1 | public static int findTopK(int[] array, int left, int right, int k) { |
空间换时间
如果所有N个数都是正整数,且他们的取值范围并不大,可以考虑申请空间,记录每个整数出现的次数,然后再从大到小取最大的K个。实际就是利用计数排序的思想。 假设所有整数都在(0,maxN)区间,利用一个数组count[maxN]来记录每个整数出现的次数。count[i]表示整数i在N个数中出现的次数。只需要扫描一遍就可以得到count数组,然后寻找第K大的元素。算法实现如下:
1 | public static List<Integer> findTopK(int[] array, int k) { |
这是一个典型的以空间换取时间的做法。当数组中取值范围比较大时,是及其浪费空间的。如[3,1…9999],为了求出最大的K个元素,需要额外申请一个长度为10000的数组。
Rand7
问题描述: 已知rand5能等概率产生1, 2, 3, 4, 5, 现要用rand5来实现rand7(rand7的意思是要等概率产生1, 2, 3, 4, 5, 6, 7)
- 用rand5产生等概率的0, 1, 2, 3, 4,准备插入到下一步的等间距数组中, 使得插入后, 刚好合适。
- 用rand5产生等概率的0, 1, 2, 3, 4, 然后为了被插入, 将其散开成0, 5, 10, 15, 20.
- 将第一步插入 到第二步中, 于是, 就形成了0, 1, 2, 3, 4, 5, 6, 7, 8, …, 20, 21, 22, 23, 24. 然后就很容易等概率地生成1, 2, 3, 4, 5, 6, 7了。
只出现一次的数字
给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
1 | class Solution { |
给定一个整数数组 nums,其中恰好有两个元素只出现一次,其余所有元素均出现两次。 找出只出现一次的那两个元素。
1 | class Solution { |
求众数
给定一个大小为 n 的数组,找到其中的众数。众数是指在数组中出现次数大于 ⌊ n/2 ⌋ 的元素。
1 | //从第一个数开始count=1,遇到相同的就加1,遇到不同的就减1,减到0就重新换个数开始计数,总能找到最多的那个 |
鸡蛋掉落
标准版
有2个鸡蛋,从100层楼上往下扔,以此来测试鸡蛋的硬度。比如鸡蛋在第9层没有摔碎,在第10层摔碎了,那么鸡蛋不会摔碎的临界点就是9层。
问:如何用最少的尝试次数,测试出鸡蛋不会摔碎的临界点?
二分法
平方根法
进阶版
你知道存在楼层 F ,满足 0 <= F <= N 任何从高于 F 的楼层落下的鸡蛋都会碎,从 F 楼层或比它低的楼层落下的鸡蛋都不会破。
每次移动,你可以取一个鸡蛋(如果你有完整的鸡蛋)并把它从任一楼层 X 扔下(满足 1 <= X <= N)。
你的目标是确切地知道 F 的值是多少。
无论 F 的初始值如何,你确定 F 的值的最小移动次数是多少?
动态规划